Following on from my previous posts on tSQLt, I've recorded a training course for Pluralsight which goes through how to use tSQLt and SQL Test to unit test your databases, to give you confidence in your database code.
I've used SQL 2012 Developer Edition for the course, but tSQLt will work with any version of SQL from 2005 SP2 upwards, and you don't need to purchase SQL Test to follow along.
Pluralsight offer a 10 day free trial of their service, so you can try before you buy.
My three hour course takes you through why you would want to unit test, and introduces the tools we will use. I then show you how to write your first unit test, before going into more detail on how to isolate dependencies, and the variety of things to test for. We look at how to unit test in your day to day workflow, before looking at some more advanced topics, like using unit tests to enforce development standards.
The course assumes you are familiar with T-SQL code and stored procedures, but have not used tSQLt before, so it should be of interest to those new to the concept of database unit testing as well as those who have dabbled with tSQLt or SQL Test.
To see the course, or the detailed list of content, click here.
Friday, 13 December 2013
Tuesday, 10 December 2013
T-SQL Tuesday #49: Wait for It …

This is a post inspired by the T-SQL Tuesday blog party series; this month (#49) the topic is hosted by Robert Davis (@SQLSoldier). Robert challenged us to "give us your most interesting post involving waits". Which reminds me...
I used to live in a little hamlet in the north of Devon. The closest post office was about 5 miles away, and this was so far in the sticks that the post office and village shop were second only to the pub for being the centre of the conversationalist's universe. As this was both in one, you can imagine how much information flowed through that little building!
However, this wasn't all great news if you were in a hurry. Occasionally, I'd pop across to post some item that needed weighing, or proof of purchase, and discover that in order to buy my stamp and post the letter, I'd have to wait for the conversation in front of me to finish. There was only one serving position, so It wasn't unknown for a queue with two people in it to take upwards of 45 mins. There was a similar queue if you wanted to buy stationary or similar from the shop desk (it seems to be a British tradition that the post office queue is separate from the queue for the rest of the shop - even if the same person then serves you).
So, I hear you ask, where is this going? What relevance does this have? Well, the post office / corner shop metaphor is a reasonable one for some of the waits in SQL Server (and I believe a reasonable attempt at a somewhat humourous twist on the topic at hand).
We have the queue - the "to do" list, of people waiting to be served - queries or processes which are waiting to be worked on. We have the thing they are waiting for - time at the counter - this could represent resources such as RAM, with the worker who serves us as the CPU. We have the question of whether there is more than one person serving at a time (Parallelism). Perhaps we have a post office and a corner shop (2 instances) in the same building (server).
What about the shop owner (DBA)? He has to plan for whether he has enough capacity (resources) for the people coming to the shop (workload). He needs a big enough doorway (IO) to cope with the people coming and going, with their parcels (data). He doesn't want to pay for (license) more staff than he has need for, but neither does he want people to dread coming to his shop (Server) to do their business (get, put or update the required data) because it takes too long - otherwise he may lose his contract to run the post office (job)!
In the day to day process of managing the flow of people through a post office, our shop owner needs to ensure he has information about why people aren't happy, so that he can solve it. Our DBA has these tools however, and one of these is the wait stats view sys.dm_os_wait_stats, which gives the aggregated view of waits that the system has encountered - the equivalent of an anonymous survey of all customers using the shop during the day asking what they waited for, which gives us the tools to see where we might be stretched for resources. As with the survey, sometimes the results are a little misleading, and so we need to dig further to cure the problem, but it gives a good place to start looking.
A lot of the problems in this simple metaphor are familiar to us all, but I find that relating the technical details to a real world environment can help to clearly explain why things aren't working, and perhaps help us to solve a constraint on our work.
Lastly, yes I know that this was strictly about waits involving post, rather than a post involving waits... ;-)
Saturday, 30 November 2013
Using Insert Exec with multiple result sets
Sometimes, there is a need to get result sets from a stored procedure into a table. One deceptively simple method is with a Insert..Exec statement.
This works fine for a simple example such as:
This returns our table, as we might expect.

However, the situation gets a little more complex if we return from our stored procedure two datasets, which have the same metadata:
Now, when we run our code to capture the dataset we get:
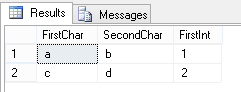
This is perhaps a little surprising - and gives us the scenario where the results from our stored proc are indistinguishable from what we would get if we had:
However, if we accessed this same data via a different method (e.g. from CLR or an application looking at distinct result sets) these would be distinguishable. This is in my opinion counter intuitive behaviour which can give us a misleading result.
Suppose you were capturing a result which would be either in the first result set or in the second (the other to be returned empty). It follows that you couldn't use Insert..Exec to capture this as you would be unable to determine which set had caused it. In other words, the results returned using Insert Exec with the following two queries are indistinguishable:
Try running the queries individually and you will see what I mean!
This is something to be aware of, both when coding and testing stored procedures, especially if Insert..Exec is used to capture information.
This works fine for a simple example such as:
USE tempdb
GO
CREATE PROC dbo.tempproc AS
SELECT 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
GO
DECLARE @table TABLE
(
FirstChar CHAR(1) ,
SecondChar CHAR(2) ,
FirstInt INT
)
INSERT @table
EXEC dbo.tempprocSELECT * FROM @tableThis returns our table, as we might expect.
However, the situation gets a little more complex if we return from our stored procedure two datasets, which have the same metadata:
ALTER PROC dbo.tempproc AS
SELECT 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
SELECT 'c' AS FirstChar ,
'd' AS SecondChar ,
2 AS FirstInt
GONow, when we run our code to capture the dataset we get:
This is perhaps a little surprising - and gives us the scenario where the results from our stored proc are indistinguishable from what we would get if we had:
ALTER PROC dbo.tempproc AS
SELECT 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
UNION ALL
SELECT 'c' AS FirstChar ,
'd' AS SecondChar ,
2 AS FirstInt
GOHowever, if we accessed this same data via a different method (e.g. from CLR or an application looking at distinct result sets) these would be distinguishable. This is in my opinion counter intuitive behaviour which can give us a misleading result.
Suppose you were capturing a result which would be either in the first result set or in the second (the other to be returned empty). It follows that you couldn't use Insert..Exec to capture this as you would be unable to determine which set had caused it. In other words, the results returned using Insert Exec with the following two queries are indistinguishable:
ALTER PROC dbo.tempproc AS
SELECT TOP 0 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
SELECT 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
GO
ALTER PROC dbo.tempproc AS
SELECT 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
SELECT TOP 0 'a' AS FirstChar ,
'b' AS SecondChar ,
1 AS FirstInt
GOTry running the queries individually and you will see what I mean!
This is something to be aware of, both when coding and testing stored procedures, especially if Insert..Exec is used to capture information.
Tuesday, 29 October 2013
Testing for Exceptions with tSQLt
I've recently been looking at two relatively new pieces of functionality in tSQLt, the unit testing framework that underpins Red Gate software's SQL Test.
I've written and presented about SQL Test and tSQLt before, including how to upgrade SQL Test to the latest version of tSQLt, but in case you've not been aware of these tools previously, tSQLt is a unit testing framework which allows SQL Server developments to be properly unit tested, within the database, and SQL Test is a user interface which makes it easy to see and run tests.
One of my gripes in the past has been the limited functionality for testing exceptions. Most applications will raise an error in some place or another, hopefully well captured and handled, but not always. Often the database needs to raise an error to feed back to the application, and this should be tested in the same way as any other requirement.
The problem which I have come across in the past is in how to prevent the inbuilt transaction handling capabilities of SQL server from rolling back the test transaction if you hit an error (tSQLt runs all tests in a transaction). This can cause the test to error, which of course is contrary to the desired behaviour. Previously I've had to use a catch-try block to set a variable which I then evaluated to check whether an exception had been raised.
That's where this new functionality comes in - we have two new functions, ExpectException and ExpectNoException which encapsulate the following command, watching for an exception, and pass or fail the test appropriately. ExpectException can even look out for a specific message, and fail if you get a different message.
So, a demonstration. Consider the following stored procedure:
This will create a procedure that will error if you do not supply a valid input - a number 1. Clearly this is a fabricated example, but it illustrates the point.
This can be tested with the following test:
Which will fail the test if an exception is not raised. It is even possible to test for a specific message using ERROR_MESSAGE to determine this in the catch block.
The new functionality however makes this much more user friendly as a test, which of course makes this more maintainable.
So how would this test now look?
As you can see, this is much simpler, and easy to see what is being accomplished. It is also possible to check for specific messages (as has been done here), severities and states, as well as using pattern matching (for example for date or time based messages) as part of this same statement.
It is worth noting that this is defined in tSQLt as an expectation rather than an assertion, which may catch some out in terms of naming, but is sensible to denote that the expectation is before the code under test is run, whereas assertions happen afterwards.
I've written and presented about SQL Test and tSQLt before, including how to upgrade SQL Test to the latest version of tSQLt, but in case you've not been aware of these tools previously, tSQLt is a unit testing framework which allows SQL Server developments to be properly unit tested, within the database, and SQL Test is a user interface which makes it easy to see and run tests.
One of my gripes in the past has been the limited functionality for testing exceptions. Most applications will raise an error in some place or another, hopefully well captured and handled, but not always. Often the database needs to raise an error to feed back to the application, and this should be tested in the same way as any other requirement.
The problem which I have come across in the past is in how to prevent the inbuilt transaction handling capabilities of SQL server from rolling back the test transaction if you hit an error (tSQLt runs all tests in a transaction). This can cause the test to error, which of course is contrary to the desired behaviour. Previously I've had to use a catch-try block to set a variable which I then evaluated to check whether an exception had been raised.
That's where this new functionality comes in - we have two new functions, ExpectException and ExpectNoException which encapsulate the following command, watching for an exception, and pass or fail the test appropriately. ExpectException can even look out for a specific message, and fail if you get a different message.
So, a demonstration. Consider the following stored procedure:
CREATE PROC dbo.MyProc @Myvar INT
AS
IF @Myvar != 1BEGIN
RAISERROR ('Variable is not one!',16,1)ENDGOThis will create a procedure that will error if you do not supply a valid input - a number 1. Clearly this is a fabricated example, but it illustrates the point.
This can be tested with the following test:
EXEC tSQLt.NewTestClass @ClassName = N'ExceptionTesting' -- Test class creationGO
CREATE PROC ExceptionTesting.[test wait for exception old method]AS
DECLARE @error INT = 0 /* flag to indicate that an error was raised */BEGIN TRY EXEC dbo.MyProc @Myvar = 2 /* the code under test */END TRYBEGIN CATCH SET @error = 1 /* Set variable as an error was raised */END CATCH
IF @error != 1 /* Raise an error if the variable has not been set */ EXEC tSQLt.Fail 'Exception was not raised'GOWhich will fail the test if an exception is not raised. It is even possible to test for a specific message using ERROR_MESSAGE to determine this in the catch block.
The new functionality however makes this much more user friendly as a test, which of course makes this more maintainable.
So how would this test now look?
CREATE PROC ExceptionTesting.[test wait for exception new method]AS
EXEC tSQLt.ExpectException @ExpectedMessage = 'Variable is not one!' EXEC dbo.MyProc 2
GOAs you can see, this is much simpler, and easy to see what is being accomplished. It is also possible to check for specific messages (as has been done here), severities and states, as well as using pattern matching (for example for date or time based messages) as part of this same statement.
It is worth noting that this is defined in tSQLt as an expectation rather than an assertion, which may catch some out in terms of naming, but is sensible to denote that the expectation is before the code under test is run, whereas assertions happen afterwards.
Monday, 30 September 2013
A word on data types
I came across a situation today where there was clearly confusion as to data types and numeric representation.
The basic issue at hand was how to represent a large number in SQL Server.
Now, SQL Server has a number of data types, which are essentially ways of representing data so that SQL Server can understand something about them. Each bit of data in SQL server needs to have one of these types. Some of these are used for numbers, and that is where our problem starts.
There are specific ranges of data that can be represented in each, and a corresponding amount of storage used. Clearly this is a concern for DBAs and DB designers who need to calculate storage space for millions of potential records. For example, the Numeric / Decimal types have the following possibilities:
The basic issue at hand was how to represent a large number in SQL Server.
Now, SQL Server has a number of data types, which are essentially ways of representing data so that SQL Server can understand something about them. Each bit of data in SQL server needs to have one of these types. Some of these are used for numbers, and that is where our problem starts.
There are specific ranges of data that can be represented in each, and a corresponding amount of storage used. Clearly this is a concern for DBAs and DB designers who need to calculate storage space for millions of potential records. For example, the Numeric / Decimal types have the following possibilities:
Precision
|
Storage bytes
|
|---|---|
1 - 9
|
5
|
10-19
|
9
|
20-28
|
13
|
29-38
|
17
|
What this really means is that a number with a precision of 10 takes up nearly twice the storage space of a number with a precision of 9, but that storage space is only affected when you get beyond certain values - which may mean that you can use more precision for no storage space cost. Precision here is the number of digits that are stored (the total number including those both to the left and right of the decimal point).
The general rule I use is that one should use an appropriate type for the meaning of the data (i.e. if you're storing a number, use a type that is recognised as a number, if you are storing text, use a character-based type, if you are storing a date and time, use a type designed for the purpose, etc).
Of course, there is an obvious problem here. What can we do to store a number that has 39 digits in it?
Well, you cannot store a number in a data type that is outside the range of it. You need to pick an appropriate value. There are two solutions here - The application could report an error as the data is not able to be represented, or (more sensibly) the appropriate data type should be used. For some applications, you may only care about the significant digits (and not the final accuracy) so a float data type may be appropriate.
These are decisions that ideally would be taken by a database designer before an application is commissioned with full knowledge as to the intended use of the field, and certainly changing data types takes communication between various parties as you would ideally change the data type in the application, and everywhere that data is used in the database, to minimise implicit conversions and any resulting performance issues or rounding / truncation.It is something to be very careful of in an agile environment where you may find that data changes during development.
A word on the storage of numbers. If you are looking to store the data '9E10' then this could be a string data type (a digit nine, an E, a one and a zero), perhaps an equipment model number, or it could be representing 90000000000 (9*10^10). This is one reason why the data type is important, and typed data is more meaningful than untyped data. It would be stored differently, depending on the data type, and to SQL Server these different interpretations are not necessarily the same information (although if implicitly converted they could be perceived as such). This can lead to unexpected behaviour from your application.
Dates have a similar ambiguity to them, but with the added ambiguity that you don't know if 3/2/13 represents the 3rd of Feb (UK format) or 2nd of March (US format). For this reason it is always a good idea to use a specific date-based data-type (there are some such as the Date type that only store the day, and others such as datetime, datetime2 or smalldatetime that store various precisions of time as well). If you must use a string type to represent data (for example in printed output) then it is advisable to use an unanbiguous format, such as ISO8601 detailed - CCYY-MM-DD.
I hope this has clarified some of the uncertainty over date types.
Tuesday, 13 August 2013
What happens when the audit trail meets a data migration?
This is a post inspired by the T-SQL Tuesday blog party series; this month (#45) the topic is hosted by SQLMickey. The topic this month is Auditing, so I thought I'd write some thoughts on how to deal with auditing when doing a system migration.
Most systems have an audit trail of sorts, for legal or compliance reasons, or possibly just to make the system administrator's life easier. The idea is that this forms a permanent record of who did what, when.
What happens to this when it's time to change the system or migrate the data out to a new system? How so you retain the audit trail, both of the old system and prove the methods used to transfer the data haven't changed it?
There are many types of audit trail, including paper based ones, but during IT projects focus is usually concentrated on the electronic ones built into systems. Usually, you cannot import the trail from an old system into your new system, as that would imply an editable audit trail. This means that you have to use another method in order to maintain traceability and the link between the old system including the data in it and the new.
If the old system is being maintained then it may be sufficient to simply keep the old system logs where they are, and keep accurate records as proof of how this was transferred to the new system.
During the planning stages of an ETL migration it is likely that documentation will have been developed and this can be retained as proof of how the data was to be migrated.
During the planning stages of an ETL migration it is likely that documentation will have been developed and this can be retained as proof of how the data was to be migrated.
This may be in the form of data maps, or instructions, but needs to be at the detailed level necessary to provide the required traceability.
By migrating data between systems you break the continuity of the records, so it is important that the records you keep are sufficient, and I find that it's best to involve the person from the business who has to defend items to an external auditor at an early stage, as they need to be comfortable that sufficient records are kept. This may involve data that will change as part of the migration, particularly when changing between systems that have a different way of organising data internally - but in my experience this is not important if proper records are kept such that the data can be related - in either direction - in the future.
If an old system is being decommissioned, it is important to decide whether the audit trail needs to be kept, and if so for how long, as this may be different to how long the data itself needs to be kept. You may also have decisions to make as to the form in which the data is kept - often this is linked to the cost of storage, for example if storing it in the previous system means that a licence would need to be maintained to access the information, but the sanctity of the audit trail must also be considered if the data is to be exported from the system.
A final point I would make is that however you retain this continuity between the data before and after migration, it is sensible to get someone else to review your work - both in terms of requirements and implementation, and document it so that even your decisions about the audit trail are audited.
Saturday, 27 July 2013
Inserting words in varchars
It recently occurred to me that not all SQL developers are aware of all of the ways to update string data in SQL server.
Let's consider a simple table:
Let's put some data in it:
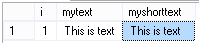
So, let's say you want to insert a word into our text. There are several ways of doing it:
The "left-write-right" method:

This has simplicity, and is easy to understand for the new coder, but is not the only method. You can use the STUFF function:

However, I recently found a method I had been previously unaware of, specifically for the varchar(max), nvarchar(max), varbinary(max) types (it doesn't work on, for example, other varchar fields as they are not treated the same way within SQL server). This is the .WRITE method, used to put some text at the end of a string:
The syntax is:
(if StartPosition is null, the end of the string to be updated is used)
Now, given the alternatives and limitations, why would you use .WRITE? Well, whereas other methods need to read the text, update it, and write it, this only needs change the updated data. This is important where you have large data, as putting text on the end of the column is minimally logged (if you are in bulk-logged or simple modes) which can be faster. This MSDN (see the section "Updating Large Value Data Types") notes that it is most effective if 8060 bytes are inserted at a time.
Let's consider a simple table:
CREATE TABLE TempStuff
(
i INT IDENTITY(1, 1)
PRIMARY KEY ,
mytext VARCHAR(MAX) ,
myshorttext VARCHAR(1000)
)Let's put some data in it:
INSERT dbo.TempStuff
( mytext, myshorttext )VALUES ( 'This is text', -- mytext - varchar(max)
'This is text' -- myshorttext - varchar(1000)
)
SELECT * FROM dbo.TempStuffSo, let's say you want to insert a word into our text. There are several ways of doing it:
The "left-write-right" method:
UPDATE dbo.TempStuffSET mytext = LEFT(mytext, 7) + ' test' + RIGHT(mytext, LEN(mytext) - 7) ,
myshorttext = LEFT(myshorttext, 7) + ' test' + RIGHT(myshorttext, LEN(myshorttext) - 7)
SELECT * FROM dbo.TempStuffThis has simplicity, and is easy to understand for the new coder, but is not the only method. You can use the STUFF function:
UPDATE dbo.TempStuffSET mytext = STUFF(mytext, 9, 0, 'stuffed ') ,
myshorttext = STUFF(myshorttext, 9, 0, 'stuffed ')
SELECT * FROM dbo.TempStuffHowever, I recently found a method I had been previously unaware of, specifically for the varchar(max), nvarchar(max), varbinary(max) types (it doesn't work on, for example, other varchar fields as they are not treated the same way within SQL server). This is the .WRITE method, used to put some text at the end of a string:
UPDATE dbo.TempStuffSET mytext.WRITE(' written at the end',NULL,0)
SELECT * FROM dbo.TempStuffThe syntax is:
StringToUpdate.WRITE(Newtext,StartPosition,CharactersToDelete)
(if StartPosition is null, the end of the string to be updated is used)
Now, given the alternatives and limitations, why would you use .WRITE? Well, whereas other methods need to read the text, update it, and write it, this only needs change the updated data. This is important where you have large data, as putting text on the end of the column is minimally logged (if you are in bulk-logged or simple modes) which can be faster. This MSDN (see the section "Updating Large Value Data Types") notes that it is most effective if 8060 bytes are inserted at a time.
Tuesday, 2 July 2013
Book Review - SQL Server Transaction Log Management
I was recently sent a review copy of "SQL Server Transaction Log Management " by Tony Davis and Gail Shaw, a new book from Red Gate (who publish the SimpleTalk series of websites and books.
" by Tony Davis and Gail Shaw, a new book from Red Gate (who publish the SimpleTalk series of websites and books.

This book is part of the Stairway series of books, and as such tackles a narrow subject, but from the very basics to an expert level. I found that the process of building from simple basics to a more in depth discussion of the technical details was accessible both to those who might have inherited a system and need to know how to properly configure it to minimise risk, and those who have a more detailed understanding.
Whilst this book does tackle data recovery, it is more about prevention and putting yourself in the position of avoiding the disaster in the first place. The process used in this book allows you to take a look at the reasons why you would choose to manage your transaction log in various ways, what implications this might have, and how that might impact upon your service level agreements (time and amount of potential data loss in a disaster) to the business. It deals with why and how to back up the transaction log in order to minimise data loss, and the implications of a corruption or loss of a log backup.
The book has detailed chapters on Full and Bulk Logged recovery modes, and even deals with Simple mode, and the ways in which the transaction log is used in each of them. It also goes through common scenarios (run away growth of a transaction log, disaster recovery, switching modes) to examine the implications and ways forward for each. It also looks at how to optimise your log so that you get the best performance for your intended use of the system, and how to monitor the log to check it is working optimally.
The style of the book is very much that of a taught example, and as such it allows the reasons why a course of action is desirable (or not) to be reinforced with a worked example, and specifies where decisions have been taken that aren't ideal for a production environment.
This is the sort of book I would give to a Junior DBA, to familiarise him or her with why transaction logs are configured as they are, and will keep for my own shelf to remind myself of the more technical details as to what is going on inside SQL Server in various log operations.
This book is part of the Stairway series of books, and as such tackles a narrow subject, but from the very basics to an expert level. I found that the process of building from simple basics to a more in depth discussion of the technical details was accessible both to those who might have inherited a system and need to know how to properly configure it to minimise risk, and those who have a more detailed understanding.
Whilst this book does tackle data recovery, it is more about prevention and putting yourself in the position of avoiding the disaster in the first place. The process used in this book allows you to take a look at the reasons why you would choose to manage your transaction log in various ways, what implications this might have, and how that might impact upon your service level agreements (time and amount of potential data loss in a disaster) to the business. It deals with why and how to back up the transaction log in order to minimise data loss, and the implications of a corruption or loss of a log backup.
The book has detailed chapters on Full and Bulk Logged recovery modes, and even deals with Simple mode, and the ways in which the transaction log is used in each of them. It also goes through common scenarios (run away growth of a transaction log, disaster recovery, switching modes) to examine the implications and ways forward for each. It also looks at how to optimise your log so that you get the best performance for your intended use of the system, and how to monitor the log to check it is working optimally.
The style of the book is very much that of a taught example, and as such it allows the reasons why a course of action is desirable (or not) to be reinforced with a worked example, and specifies where decisions have been taken that aren't ideal for a production environment.
This is the sort of book I would give to a Junior DBA, to familiarise him or her with why transaction logs are configured as they are, and will keep for my own shelf to remind myself of the more technical details as to what is going on inside SQL Server in various log operations.
Friday, 21 June 2013
Adding sequential values to identical rows
I was recently presented with a requirement whereby I had a list of orders, with parts, and a list of orders with serial numbers with which I needed to update the original table.
Let's look at the OrderedParts table, which contains a list of the parts used on a customer orders:
This seems straightforward for order number 1252 as the parts are unique, but consider that the orders could be for multiple of the parts, and the only way of telling rows apart is with the serial number, as in order 1234.
Here is our table of available parts with serial numbers:
We will want the OrderParts table to be updated such that the serial numbers X112 and X113 each appear once in it, showing those serial numbers are used in the order.
Let's look at the OrderedParts table, which contains a list of the parts used on a customer orders:
| OrderNo | PartNo | SerialNo |
| 1234 | ABC1 | |
| 1234 | ABC1 | |
| 1252 | XYZ3 | |
| 1252 | HHJ3 |
This seems straightforward for order number 1252 as the parts are unique, but consider that the orders could be for multiple of the parts, and the only way of telling rows apart is with the serial number, as in order 1234.
Here is our table of available parts with serial numbers:
| PartNo | SerialNo |
| ABC1 | X112 |
| ABC1 | X113 |
| XYZ3 | I330 |
| HHJ3 | K283 |
We will want the OrderParts table to be updated such that the serial numbers X112 and X113 each appear once in it, showing those serial numbers are used in the order.
This presents us with a problem in the traditional update statement; how do we join these tables together such that we can update the records correctly?
Well, let us consider the an update statement:
/* Code snippet coded by Dave Green @d_a_green - June 2012*/
/* Set up tables*/DECLARE @OrderedParts TABLE
(
OrderNo INT NOT NULL ,
PartNo VARCHAR(100) NOT NULL ,
SerialNo VARCHAR(100) NULL
)
INSERT @OrderedPartsVALUES ( 1234, 'ABC1', NULL )
, ( 1234, 'ABC1', NULL )
, ( 1252, 'XYZ3', NULL )
, ( 1252, 'HHJ3', NULL )
DECLARE @Stock TABLE
(
PartNo VARCHAR(100) NOT NULL ,
SerialNo VARCHAR(100) NOT NULL
)INSERT @Stock
( PartNo, SerialNo )VALUES ( 'ABC1', 'X112' )
, ( 'ABC1', 'X113' )
, ( 'XYZ3', 'I330' )
, ( 'HHJ3', 'K283' )
--Try joining the tables on the part number
UPDATE @OrderedPartsSET SerialNo = Stock.SerialNoFROM @OrderedParts
INNER JOIN @Stock Stock ON [@OrderedParts].PartNo = Stock.PartNo
SELECT * FROM @OrderedParts
That produces the result:
Which, as you can see has done the instances where only one instance of each part was used in the order (order 1252) , but has not covered instances where multiple of the same part was used in the order (order 1234).
So how can we get round this?
Well, I chose to think about them in terms of "we want the first matching part in the first row, and the second matching part in the second row". This got me thinking about how we arrange the rows - numerically, and about using the ROW_NUMBER() function.
So, we can easily add a row number by using something like:
So - we need to give both tables a row number, and then use this as part of our join criteria for the update:
Using the row number as a joining criteria in this way gives the answer:
This has achieved our desired result, of each available serial number being used uniquely within the order.
| OrderNo | PartNo | SerialNo |
| 1234 | ABC1 | X112 |
| 1234 | ABC1 | X112 |
| 1252 | XYZ3 | I330 |
| 1252 | HHJ3 | K283 |
Which, as you can see has done the instances where only one instance of each part was used in the order (order 1252) , but has not covered instances where multiple of the same part was used in the order (order 1234).
So how can we get round this?
Well, I chose to think about them in terms of "we want the first matching part in the first row, and the second matching part in the second row". This got me thinking about how we arrange the rows - numerically, and about using the ROW_NUMBER() function.
So, we can easily add a row number by using something like:
SELECT *,ROW_NUMBER() OVER (ORDER BY PartNo)FROM @OrderedPartsSo - we need to give both tables a row number, and then use this as part of our join criteria for the update:
UPDATE OrderedParts
SET SerialNo = Stock.SerialNo
FROM ( SELECT *,
ROW_NUMBER() OVER ( ORDER BY PartNo ) AS RowNumber
FROM @OrderedParts
) AS OrderedParts
INNER JOIN ( SELECT *,
ROW_NUMBER() OVER ( ORDER BY PartNo ) AS RowNumber
FROM @Stock
) AS Stock ON OrderedParts.PartNo = Stock.PartNo
AND OrderedParts.RowNumber = Stock.RowNumber
Using the row number as a joining criteria in this way gives the answer:
| OrderNo | PartNo | SerialNo |
| 1234 | ABC1 | X112 |
| 1234 | ABC1 | X113 |
| 1252 | XYZ3 | I330 |
| 1252 | HHJ3 | K283 |
This has achieved our desired result, of each available serial number being used uniquely within the order.
Tuesday, 14 May 2013
T-SQL Tuesday #42 - The Long and Winding Road
Have you heard of T-SQL Tuesday? I hadn't until recently, but it's a series of monthly blogs started by Adam Machanic ( blog | twitter ) some years ago (well, 42 months ago, one presumes) for all to participate in. The idea is that each month someone hosts it, that person sets a topic which we all post to and link our post to twitter using the hash tag #tsql2sday.
This month, the topic is set ("hosted") by SQL MVP Wendy Pastrick ( blog | twitter ). She's entitled it "The Long and Winding Road" and challenged us all to post about how you got to where you are, and what you plan to do next, noting what technologies are key to your interests or successes. Here's my story - and first T-SQL Tuesday post...
I've been using databases (predominantly of the Microsoft variety) for more years than I care to remember now, having started with data entry before rapidly moving on to programming Access (v95? or possibly as early as v.2.0) databases as part of my first full time job (not what I thought I'd be doing, but a good use of what was until then just a hobby). I soon moved onto using SQL Server as well, in about the year 2000. I've dabbled with other technologies, spent time programming, dealt with business administration, but generally it was data management that I enjoyed, and that remains my area of focus. The technology has changed somewhat, but the core concepts remain remarkably unchanged. I've changed how I work, have worked with large companies and small, and every challenge is different.
Fundamentally I think that the ability to speak to all levels of the business is required as a data professional - you need to be able to connect with the CEO who wants a key metrics view of the business' information, the data entry clerk who has to record the information, the developer who has to build the system, the IT department who have to manage it and the CFO who wants it all done for no money. Of course none of them want to hear that the solution isn't absolutely perfect (ideally with respect to what is needed in the future), or needs maintenance - but that's all part of the fun!
If I had to say what technology had changed my working life more than any other, it's probably the Internet. Not the protocols, or changes to how I interact with data, but the ability to interact with my peers on demand, and help learn by engaging with other professionals - and amateurs - as they look at their own data challenges. It's introduced me to many more fellow-professionals than I thought existed, the talked about #sqlfamily.
I recently posted about how the Internet can help you find your next role, and also how to connect with the community, and I would also point to Q&A sites like ask.sqlservercentral.com and stack overflow. They're a great source of knowledge and expertise if you need inspiration on a problem, and I have found that by digging into other peoples' questions that interest me I've learned a lot myself. This helps steer my career, by way of introducing me to new technologies I may otherwise not have looked at.
What's next for me? I'm not honestly sure. I've just (in the last week) had my first child, and so a lot is changing right now on a personal level - so it seems a good time to re-appraise my career priorities. Whatever is next, I'm sure it won't be something I could predict now, except that it will be something exciting...
Sunday, 21 April 2013
Who are you?
As the economy continues on it's somewhat flat course, there are a number of data professionals who are out of work, or finding it more difficult to find their next role.
A couple of people I know recently asked me how to give themselves an edge when looking for a new role - and my answer was simple - start a blog. I view it as one type of continuous professional development. The reasons to write about the things that you enjoy are many; here are a few:
You dedicate time to it
If you have a family, or simply a long commute, it can be difficult to find time outside the normal working day to allow you to explore areas of technology that you don't get to play with as part of your day job. I think this is essential to improving - not all learning can be as a result of your job, and often blogging allows me to explore something that interests me.
Don't be over ambitious by trying to write too frequently at first - you can always write more. Take some time to get used to writing. I usually only do one post a month, but that's right for me. I also write occasional articles on other sites, and contribute via forums etc.
You learn something more when you write about it
To fully explain something, you need to think about it. All too often we only get time to scratch the surface of topics at the periphery of our focus, but sitting down and writing something detailed about it can force you to go into more detail about what's going on, and explore how to use it properly.
You build an on-line presence.
Troy Hunt recently wrote an article about the ghost coder, and I think his point is a good one - the best way to get a positive interview experience is to have the battle half-won before you go in. My preferred way to do this is to allow those interviewing you to get to know how you think, and how you approach problems through your writing.
Of course, there are other ways to build an on-line presence - forums, Twitter, LinkedIn, etc. - and I use those too - but your blog is the presence that you can control the topic of most closely, so can most steer to your chosen direction.
There are of course some difficulties - choosing a topic, for one. Perhaps set yourself a project, and blog about your progress. Perhaps learn something online, and blog about it - that will tell you if you've learned it properly, and give you an opportunity to cement your new knowledge. You could take part in a T-SQL Tuesday, which was started a few years ago by Adam Machanic to provide a topic for lots of SQL bloggers to take part in, or perhaps pick up a forum or twitter discussion to blog about in more detail. Perhaps you will simply pick something that occurs to you whilst you're going about your day.
Whether you choose to take me up on the blog idea, or contribute to the community another way, it is something I find to be quite rewarding and hope that you do too.
A couple of people I know recently asked me how to give themselves an edge when looking for a new role - and my answer was simple - start a blog. I view it as one type of continuous professional development. The reasons to write about the things that you enjoy are many; here are a few:
You dedicate time to it
If you have a family, or simply a long commute, it can be difficult to find time outside the normal working day to allow you to explore areas of technology that you don't get to play with as part of your day job. I think this is essential to improving - not all learning can be as a result of your job, and often blogging allows me to explore something that interests me.
Don't be over ambitious by trying to write too frequently at first - you can always write more. Take some time to get used to writing. I usually only do one post a month, but that's right for me. I also write occasional articles on other sites, and contribute via forums etc.
You learn something more when you write about it
To fully explain something, you need to think about it. All too often we only get time to scratch the surface of topics at the periphery of our focus, but sitting down and writing something detailed about it can force you to go into more detail about what's going on, and explore how to use it properly.
You build an on-line presence.
Troy Hunt recently wrote an article about the ghost coder, and I think his point is a good one - the best way to get a positive interview experience is to have the battle half-won before you go in. My preferred way to do this is to allow those interviewing you to get to know how you think, and how you approach problems through your writing.
Of course, there are other ways to build an on-line presence - forums, Twitter, LinkedIn, etc. - and I use those too - but your blog is the presence that you can control the topic of most closely, so can most steer to your chosen direction.
There are of course some difficulties - choosing a topic, for one. Perhaps set yourself a project, and blog about your progress. Perhaps learn something online, and blog about it - that will tell you if you've learned it properly, and give you an opportunity to cement your new knowledge. You could take part in a T-SQL Tuesday, which was started a few years ago by Adam Machanic to provide a topic for lots of SQL bloggers to take part in, or perhaps pick up a forum or twitter discussion to blog about in more detail. Perhaps you will simply pick something that occurs to you whilst you're going about your day.
Whether you choose to take me up on the blog idea, or contribute to the community another way, it is something I find to be quite rewarding and hope that you do too.
Tuesday, 12 March 2013
I'm sure my procedure does what it should!
 Last Saturday, the 9th March, was the day for SQL Saturday 194, held in Exeter in the UK. This event was organised by the SQL South West User PASS chapter.
Last Saturday, the 9th March, was the day for SQL Saturday 194, held in Exeter in the UK. This event was organised by the SQL South West User PASS chapter.From my perspective, the event seemed very well attended, and smoothly run. There were some nice touches too, like a beer and a pasty for every attendee with which to end the day, and people I spoke to had gotten a lot from the day. It was great to see so many people talking to sponsors and getting advice on their individual questions from the community. It's always amazing how much expertise there is available for free at SQL Community events!
The next SQL Saturday in the UK is in Edinburgh in June, but you can see the list of upcoming events here. There are other community events in the UK, including SQL Bits and SQL in the City. Why not come along to one? Many also run pre-con sessions, which is a cost-effective way of getting SQL Server training.
I'd like to thank those who attended my session, and also Red Gate who were kindly able to supply me with some licenses for their SQL Test product to give away. I hope that you get started unit testing your procedures and gain confidence that they do what they should, too!
My session on unit testing databases, "I'm sure what my procedure does what it should!" used the tSQLt framework to show how to write repeatable unit tests for your databases. If you would like my session slides and scripts, they are available for download here. Please do drop me a line (I'm @d_a_green on twitter) or post a comment below if you have any further questions.
Wednesday, 20 February 2013
Upgrading your tSQLt version for SQL Test users
Those of you using Red Gate's excellent SQL Test product to have unit testing integrated within SSMS may be aware that it uses the tSQLt framework internally.
The tSQLt framework is open source and updates quite frequently, often adding new features. I have sometimes found myself needing a newly released feature, but been unable to get it from SQL Test, when Red Gate haven't yet adopted the updated version. However, there is a way that you can upgrade the version of tSQLt that a database uses, and still use the integration from SQL Test. It can be source controlled in the same way and allows you to adopt the latest version; you can also use this method to downgrade if you need to.
In this post I'm going to show you how to do it.
Firstly, let's establish what version of tSQLt you have installed. I'm going to use the example database installed by SQL Test for this post. If you haven't installed the sample, you can do this by clicking the button at the bottom of the SQL Test window (you may need to scroll down if you have a number of databases with tests in them):

This will bring up the window which allows you to add a database to SQL Test - at the bottom of which is a link to "Install Sample Database". This installs a database called tSQLt_Example.
We can see the installed version with the tSQLt.Info() function:
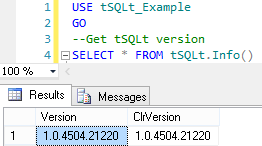
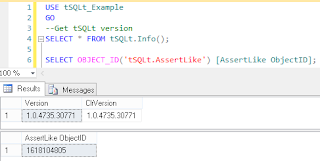
However, what if we want to use the new AssertLike function? It was only released in the latest version (1.0.4735.30771), so if we try to get the OBJECT_ID of 'tSQLt.AssertLike' we will get a null result.
We need to download the latest version of tSQLt, which you can get here. It downloads as a zip file, which contains three SQL script files:
Firstly, let's establish what version of tSQLt you have installed. I'm going to use the example database installed by SQL Test for this post. If you haven't installed the sample, you can do this by clicking the button at the bottom of the SQL Test window (you may need to scroll down if you have a number of databases with tests in them):

This will bring up the window which allows you to add a database to SQL Test - at the bottom of which is a link to "Install Sample Database". This installs a database called tSQLt_Example.
We can see the installed version with the tSQLt.Info() function:
However, what if we want to use the new AssertLike function? It was only released in the latest version (1.0.4735.30771), so if we try to get the OBJECT_ID of 'tSQLt.AssertLike' we will get a null result.
We need to download the latest version of tSQLt, which you can get here. It downloads as a zip file, which contains three SQL script files:
- SetClrEnabled.sql - this sets the server up; if you have already installed a previous version you shouldn't need to run this.
- tSQLt.class.sql - this is the file that contains the latest release, and what we need to run.
- Example.sql - this installs the latest tSQLt_Example database (with tSQLt). You don't need to run this script. It will overwrite any existing copy of the tSQLt_Example database, and install the latest version (with sample tests).
So - open up the tSQLt.class.sql file in SQL Management Studio, and run it from your existing tSQLt-enabled database. This will re-register the latest version of the CLR for tSQLt, and install the new procedures.
We can now see the version of tSQLt has been upgraded, and that we have the tSQLt.AssertLike stored procedure installed:

You will find that SQL Test will now use the new version of tSQLt in those databases that you have updated.
Upgrading tSQLt in this way doesn't change the tests you have installed, and there is no problem with running different versions of tSQLt in different databases - this means that you can upgrade projects at different times. If you have source controlled your database, then the new version of tSQLt will be source controlled with your database too, so your tests will still work (including any new tSQLt functionality) for your colleagues and in your CI system.
This method doesn't change the version that SQL Test will install if you add tests to a database, so if you hit trouble you can simply uninstall tSQLt (using tSQLt.Uninstall) and use SQL Test to re-add the framework to your database; reverting like this shouldn't alter your existing tests, but any that you have written using new functionality would cease to work as expected.
Subscribe to:
Posts (Atom)